Prečo obrázky v Googli občas "klamú" a prečo je to pre webárov dôležité vedieť?
Ak sa živíte tvorbou webu, určite ste už narazili na klasickú dilemu: ako optimalizovať obrázky pre vyhľadávače? Alt text, title atribút, názvy súborov – to všetko poznáme. Ale čo ak vám poviem, že aj napriek všetkým pokrokom v umelej inteligencii, Google Images stále občas "klame" alebo aspoň pôsobí zmätene, najmä pokiaľ ide o rozdiel medzi tým, ako AI chápe text a ako obraz?
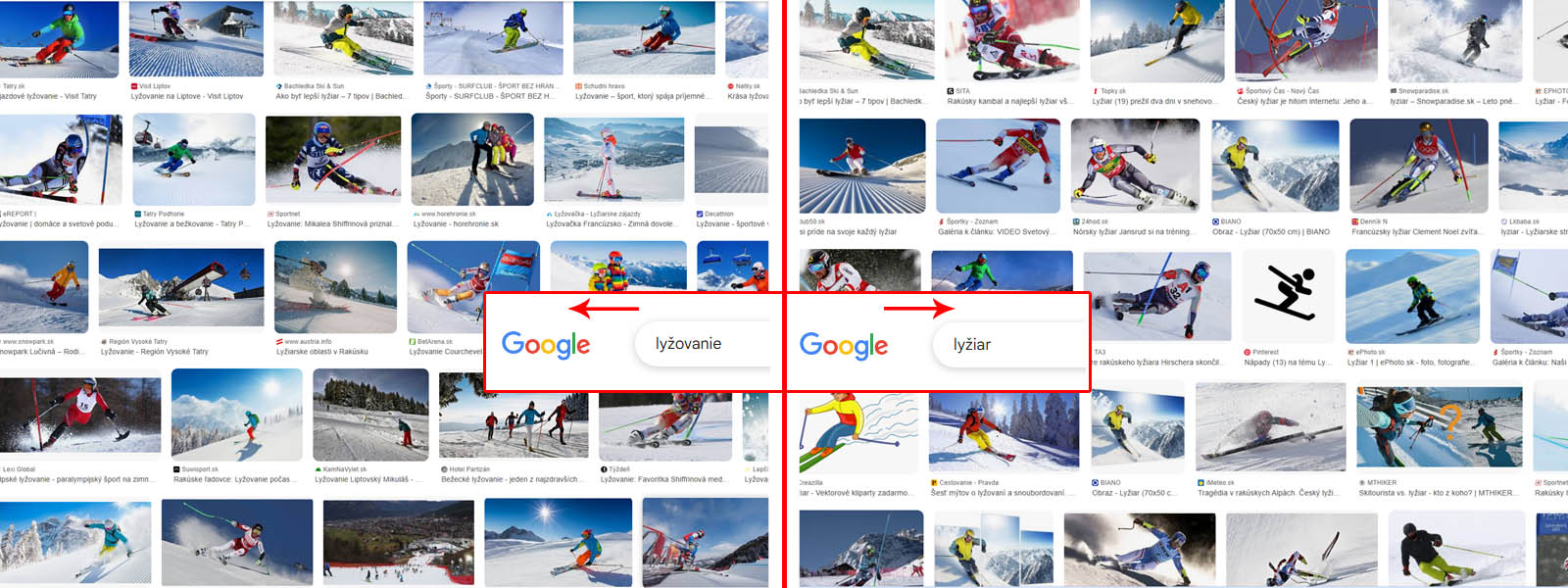
Predstavte si to: do Googlu zadáte "lyžiar" a potom "lyžovanie". Čo očakávate? Pri textovom vyhľadávaní uvidíte markantný rozdiel – pri "lyžiarovi" sú to profily športovcov, biografie, zatiaľ čo pri "lyžovaní" sú to techniky, strediská, tipy. Ale pri obrázkoch? S veľkou pravdepodobnosťou uvidíte veľmi podobné (ak nie takmer identické) obrázky: osobu na lyžiach v pohybe zo svahu. Prečo?
Obraz ako "román" vs. slovo ako "popis"
Ako ľudia vnímame svet primárne zrakom. Stačí nám zlomok sekundy na to, aby sme z obrazu vyčítali celý "román" informácií – emócie, kontext, súvislosti, spomienky. Je to intuitívne a mimoverbálne. Slovo je len naším pokusom tento "román" opísať, často neúplne a s rizikom skreslenia.
A tu je kameň úrazu pre AI:
- Ľudia: Vnímajú najprv obraz, z neho sa evokujú slová.
- AI: Je programovaná slovami (kódom) a pri "rozumeniu" obrazu sa na slová (popisky) často príliš spolieha.
Prečo textové vyhľadávanie víťazí v sémantike?
Algoritmy pre textové vyhľadávanie (NLP – Natural Language Processing) excelujú v sémantike. Jazyk má totiž explicitnú štruktúru:
- "Lyžiar" je podstatné meno pre osobu/subjekt.
- "Lyžovanie" je podstatné meno pre aktivitu/proces.
AI sa učí tieto jasné rozdiely z miliárd textových dát. Vie, že obsah o "lyžiarovi" bude pravdepodobne o profiloch, zatiaľ čo obsah o "lyžovaní" o technikách.
Kde je teda problém v obrázkovom vyhľadávaní?
Napriek tomu, že AI dokáže v obrázkoch rozpoznať neuveriteľné veci (tváre, objekty, emócie, pozície), pri vyhľadávaní sa stále príliš spolieha na textový kontext od autora obrázku.
- Vizuálna nejednoznačnosť: Ako vizuálne rozlíšite "lyžiara" od "lyžovania", ak je pre oba pojmy najrelevantnejší obrázok – osoba na lyžiach v akcii? Pre AI je ťažké rozlíšiť, či ide o subjekt alebo aktivitu, keď je vizuálne zobrazenie takmer identické.
- Prehnaná dôvera v autora: Ak dáte obrázku žaby s paličkami alt text "lyžiar", vyhľadávač to do určitej miery akceptuje. Prečo? Historicky sa vyhľadávače spoliehali na to, čo autor tvrdí o obrázku, pretože inak nevedeli, o čom je. No dnes, keď AI dokáže vizuálne analyzovať samotné pixely, je táto slepá dôvera zastaraná a otvára dvere spamu.
- AI vie, či je na obrázku muž, žena, dieťa, či je šťastný, unavený, či stojí alebo spadol – nezávisle od toho, čo jej o tom povie autor!
- Výpočtové náklady a prioritizácia: Kompletná vizuálna sémantická analýza každého obrázku na internete je obrovsky náročná. Google (a iní) musia vyvážiť presnosť s rýchlosťou a nákladmi. A boj proti textovému spamu bol historicky vyššou prioritou.
Čo to znamená pre webárov?
Aj keď sa AI neustále zlepšuje a smeruje k multimodálnemu chápaniu (kde bude text aj obraz spracúvaný spoločne a AI bude schopná validaovať obsah), momentálne je pre webárov kľúčové:
- Používajte maximálne relevantné obrázky: Neskúšajte Googlu "klamať" v alt texte. Ak máte obrázok guľáša, dajte mu alt text o guľáši. Ak máte ilustračný obrázok kuchyne, popíšte kuchyňu.
- Optimalizujte aj textový kontext: Aj keď by AI mala raz "čítať" obraz sama, zatiaľ jej stále pomáhajte jasnými popiskami, názvami súborov a relevantným textom okolo obrázku.
- Myslite na používateľa: Prezentujte obsah tak, aby bol vizuálne atraktívny a intuitívny pre ľudského návštevníka. Ak má stránka o recepte na guľáš fotku guľáša, používateľ bude spokojný a Google to ocení.
Budúcnosť vyhľadávania pre ľudí je nepochybne vizuálna. Sme dátovo preťažení textom a vizuály (vrátane videí) dokážu preniesť obrovské množstvo informácií oveľa efektívnejšie a prirodzenejšie. Ako webári, je našou úlohou nielen tvoriť krásne weby, ale aj rozumieť týmto nuansám AI, aby sme zabezpečili, že náš obsah bude nájdený a pochopený v stále vizuálnejšom svete.
Až zaregistrujeme, že sa obrázkové vyhľadávanie pre "lyžiar" a "lyžovanie" patrične odlišuje, budeme vedieť, že AI spravila ďalší veľký krok vpred vo svojom "pochopení románu" v obrazoch. A to bude pre nás všetkých skvelá správa.